Simulated Data
Creation of Dataset 2, 3 and 4
A description of the scenes and an overview of the different datasets is provided in the data section. This page is about describing in more details how the artificial datasets, namely datasets 2,3 and 4, are generated using the software TASCAR1. A brief introduction to the software is here provided but some knowledge about the structure of a TASCAR scene is assumed from the reader. More details can be found on its website.
Simulation Overview
TASCAR, or Toolbox for Acoustic Scene Creation And Rendering, is a software for rendering virtual acoustic environments in real time or offline1. It provides a fast and perceptually credible method for acoustic rendering of dynamic environments.
Virtual acoustic scenes used in tascar need at least two elements: a sound source and a receiver. Additional physical elements can be added, like reflecting surfaces, and each of those elements can be moved and orientated dynamically in space and time. Each of those building block posses other characteristics that can be modified, like the reflection coefficient of a surface or the directivity pattern (e.g. cardioid…) for sound elements. Another block of interest is the reverb plugin which implement a simple feedback delay network whose reverberation time can be defined.
In order to create the desired scene, a reverberant rooms with walls is created. A table is put at the center of this room and the sources/talkers are seated around it (only their head is considered). 10 loudspeakers are distributed across the room to create the diffuse, restaurant like, babble noise.
The receiver type used in the scenes is a 3D higher order ambisonics encoder. The ambisonic output is then convolved in the spherical harmonic domain with the array transfer function (ATF) of the mic array from EasyCom to obtain the desired 6 channels output. In each simulated scene the following outputs are obtained:
- The full scene (every source active in noisy reverberant environment)
- The direct path for each source/participant (anechoic conditions)
The interested reader is encouraged to learn more about the various plugins and their parameters from TASCAR’s manual. The different scenes used in the challenge are also provided as extra data.
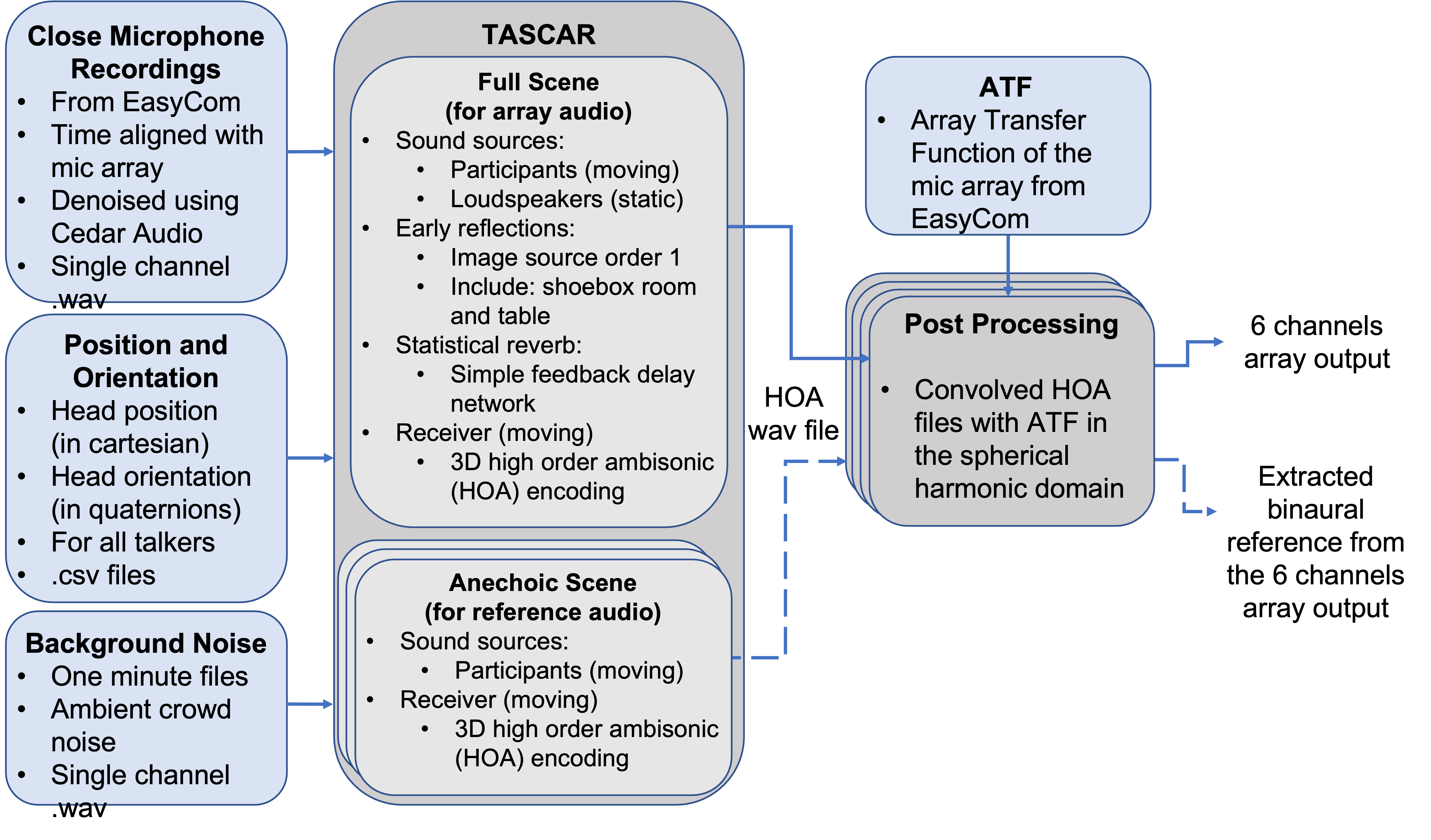 Simulated Acoustic Pipeline.
Simulated Acoustic Pipeline.
Dataset 2: EasyCom Reproduced
The purpose of this dataset is to reproduce, as closely as possible, the scenes in Dataset 1, which are taken from the EasyCom database 2.
The input source consists of the audio used in EasyCom but denoised using the proprietary noise reduction algorithm Cedar Audio DNS Two, as well as VAD activated. This denoising algorithm proved to perform very well on the EasyCom dataset. Little distortion can be heard and will not affect the metrics’ calculation as it is used as the reference of the simulations.
Dataset 3: EasyCom Augmented
Dataset 3 is an augmented version of Dataset 2. It uses the same situation where a group of people around a table are engaging in various activities but TASCAR scenes are modified to increase the acoustic diversity. The parameters that differ from the scenes of Dataset 2 are:
- The acoustic scattering coefficient of the table
- The absorption coefficient of the walls
- The size of the room
- The position of the table and, consequently, of the participants within that room
- The sound level of the 10 loudspeakers used for diffuse noise
- The positions of the 10 loudspeakers used for diffuse noise
- The head positions of the participants (slightly moved)
Those modifications are randomly generated for every Minute of every Session. The reverberation time of the room (T60) is also calculated using the Sabine formula and provided for reference in the root folder of the extra metadata.
Dataset 4: Multi Dialogue
While EasyCom is a novel dataset providing many metadata, the scenes contain a limited amount of interfering speech and in all cases, all talkers are part of the same dialogue. To evaluate the ability of algorithms to suppress speech which is not part of the listener’s current conversation (i.e. genuine interference) the multi dialogue dataset is created. In this case the people sitting around the table are engaged in unrelated dialogues and so frequently talk on top of each other.
The sentences used in this dataset are taken from the open source SLR83 corpus 3. Sentences are randomly generated alternating few seconds of silence with extracts from a single participant. Head movement and rotation, is simulated with participants looking alternatively at each other in a randomly generated pattern. Some jitter is introduced both in terms of position and orientation of the heads to reproduce real life instability. VAD, position and orientation are generated at the same frame rate as EasyCom (20Hz) and provided as extra metadata. The same modified acoustical scenes of Dataset 3 are used for Dataset 4.
References
-
G. Grimm, J. Luberadzka, and V. Homann, “A toolbox for rendering virtual acoustic environments in the context of audiology,” Acta Acustica united with Acustica, vol. 105, no. 3, pp. 566–578, 2019. ↩ ↩2
-
J. Donley, V. Tourbabin, J.-S. Lee, M. Broyles, H. Jiang, J. Shen, M. Pantic, V. K. Ithapu, and R. Mehra, “Easycom: An augmented reality dataset to support algorithms for easy communication in noisy environments,” 2021. ↩
-
I. Demirsahin, O. Kjartansson, A. Gutkin and C. Rivera, “Open-source Multi-speaker Corpora of the English Accents in the British Isles”, Proceedings of The 12th Language Resources and Evaluation Conference (LREC), pp. 6532-6541, May 2020 ↩