Data and Datasets
Description of the Scene and Datasets
The Scene(s)
The acoustic scenarios to be enhanced consist of conversations amongst a group of 3 to 6 people seated around a table with background noise and reverberation typical of a noisy restaurant. Real recordings are drawn from the recently published EasyCom database 1. These will be supplemented using simulated recordings, generated using Tascar 2, with acoustic conditions which are broadly similar to the real recordings but with increased diversity. A portion of the recorded and simulated datasets will be withheld and used for evaluation purposes (see Task and Evaluation).
EasyCom
In each scene of EasyCom, one interlocutor is deemed the “listener” and is adorned with a head-worn array as seen below. The array includes a pair of binaural microphones positioned in the listener’s ear. The other interlocutors are simply wearing a close-talking microphone. Diffuse background noise is generated by 10 loudspeakers placed around the room at varying heights emitting uncorrelated restaurant-like noises.
 Approximated positions of the microphones on the glasses. Mic 5 and 6 are positioned in the ears 1.
Approximated positions of the microphones on the glasses. Mic 5 and 6 are positioned in the ears 1.
The figure below shows the spatial arrangement of the interlocutors, loudspeakers and table used in Donley et al. 1. The room size was 6.11×7.74×3.44 m with an RT60 of 645ms.
The EasyCom database 1 includes synchronous first-person point-of-view video footage, optical tracking data for each interlocutor and extensive metadata. These data sources do not form part of the challenge. Instead they are used to derive the relevant spatial parameters which could conceivably be obtained from the multi-modal sensor data available on a future AR device. Accordingly, for each acoustic scene within the training and evaluation phases of the challenge, participants will be provided with
- 6 channel array recording,
- time aligned close microphone audio,
- synchronous head orientation data,
- synchronous DOA track for a single target talker.
Several talkers may be active in a recording and so each one will alternatively considered to be the target. More details on the structure of the provided data can be found in the download section.
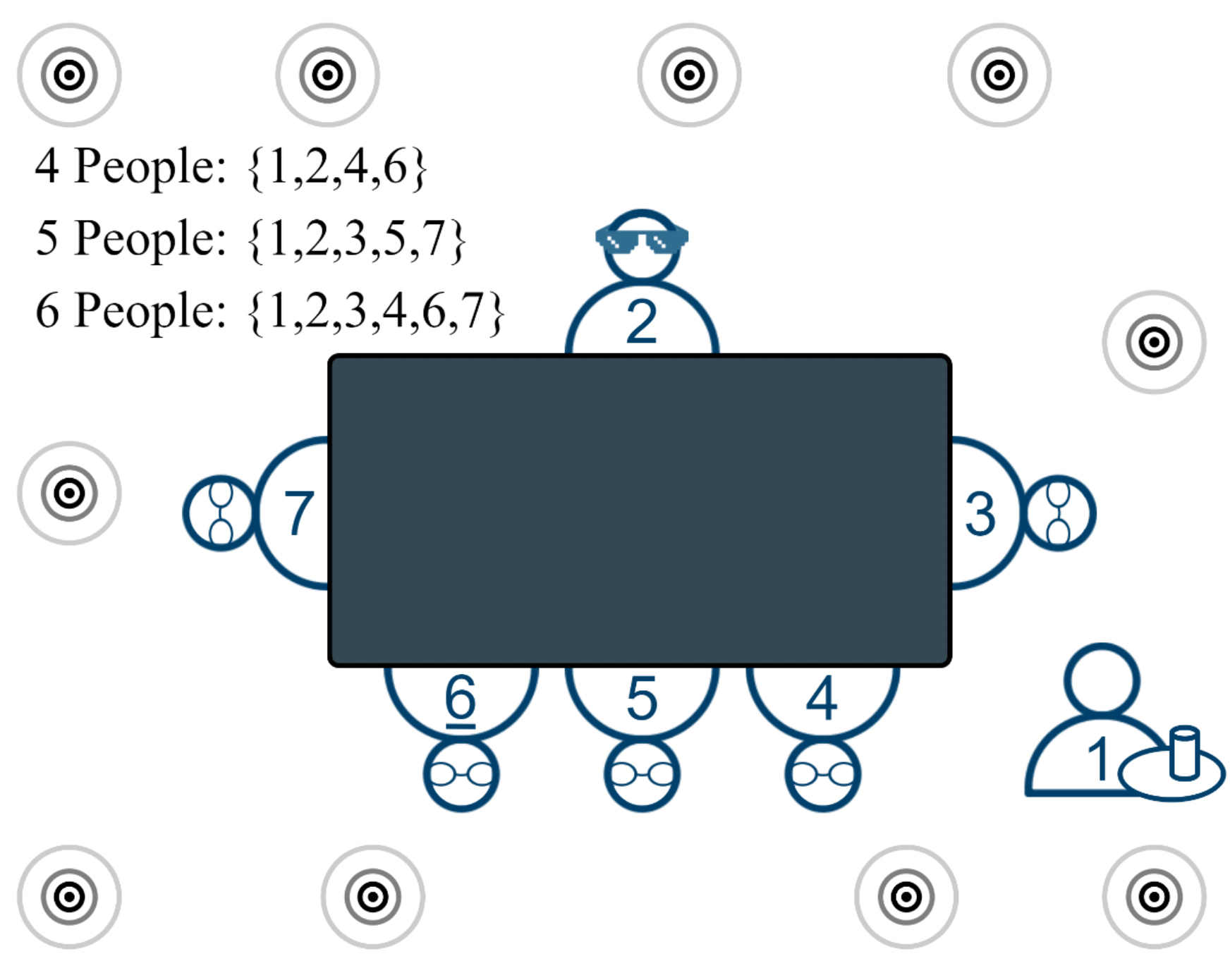 Schematic of the typical scene provided in the Challenge. Participant number 2 is wearing the microphone array glasses 1.
Schematic of the typical scene provided in the Challenge. Participant number 2 is wearing the microphone array glasses 1.
Limitations and Extensions
The strength of EasyCom comes from its realism and rich metadata. However, since the recordings are made “live”, it is impossible to define the ground truth signals at the array that an ideal enhancement would produce. Moreover, the time required to make such a set of recordings means that the possible diversity is unavoidably limited.
Reduced to its simplest form, EasyCom is defined by its audio, acoustical scene, and real time movements. To be able to evaluate intrusive metrics over a variety of scenes, SPEAR will use three simulated datasets in addition to real recordings taken from EasyCom. Each dataset addresses a different issue of EasyCom and a summary of the changes is found in the table below.
| Dataset | Scene Audio | Acoustic Scene | Head Movements |
|---|---|---|---|
| D1 | EasyCom recordings | EasyCom Scene | EasyCom movements |
| D2 | Denoised EasyCom recordings | EasyCom Scene | EasyCom movements |
| D3 | Denoised EasyCom recordings | Modified EasyCom Scene | EasyCom movements |
| D4 | Anechoic recordings | Modified EasyCom Scene | Artificial movements |
The SPEAR Datasets
Dataset 1: EasyCom Original
Content: Consists of actual recordings from EasyCom. Little to no modifications are done on the data. The main difference between the SPEAR dataset and the one provided online are the close talking microphone recordings which were time aligned with the array.
Purpose: Closest dataset from what reality can provide.
Limitations: Calculation of intrusive metrics is potentially compromised since ground truth at the array is not available.
Dataset 2: EasyCom Reproduced
Content: Reproduction of Dataset 1 using Tascar. The close talking microphone are time aligned and denoised using Cedar Audio DNS Two. Details in simulation section.
Purpose: Aim to reproduce as accurately as possible Dataset 1 for the following reasons.
- Proof of concept of the simulation procedure
- To compare the performances between real and simulated both for metrics and listening tests
- To serve as baseline comparison with Dataset 3
Limitations: Simulations can only be an approximation of real life. Denoising of close talking reference may introduce a small amount of distortion.
Dataset 3: EasyCom Augmented
Content: Using the same structure as Dataset 2, each session has had its simulated scene modified. This can result in scenes with bigger room, different RT60, different kind of noise, variations in levels… etc. Details found in the simulation section.
Purpose: To create more diversity in term of scenes for listening tests and machine learning training purposes.
Limitations: By using only EasyCom audio, a lack of diversity can be observed even with different scenes. In other words, this dataset change the scene but not the situations and more audio variety can be desired.
Dataset 4: Multi Dialogue
Content: Based on the same scene structure of # number of people talking around a table in a noisy environment, new scenes are generated using anechoic audio from a public dataset. Details in simulation section.
Purpose: This dataset has several purposes:
- Offer a dataset with inherently clean reference audio and not just denoised
- Create scenes with more interfering speech
- Create scenes more realistic in term of group conversation
Limitations: Having multiple distinct conversations occuring simultaneously makes following one particular speech more challenging. This can weight negatively in the listening tests.
References
-
J. Donley, V. Tourbabin, J.-S. Lee, M. Broyles, H. Jiang, J. Shen, M. Pantic, V. K. Ithapu, and R. Mehra, “Easycom: An augmented reality dataset to support algorithms for easy communication in noisy environments,” 2021. ↩ ↩2 ↩3 ↩4 ↩5
-
G. Grimm, J. Luberadzka, and V. Homann, “A toolbox for rendering virtual acoustic environments in the context of audiology,” Acta Acustica united with Acustica, vol. 105, no. 3, pp. 566–578, 2019. ↩