Scripts and Tools
Description of the provided scripts including the baseline model
A set of Python tools, including a baseline enhancer, are provided to demonstrate how the enhanced audio should be stored. Scripts allow to compute a range of metrics on the enhanced audio and to visualise the results. The needed csv file containing the separation of the audio into desired chunk is included in the repo. The output metric tables for all datasets in Train and Dev sets are also provided for simplicity.
Structure Summary
┬── analysis (directory): Contains all relevant scripts and files
│ ├── Processor.py (file): Python class for baseline beamformer
│ ├── SPEAR.py (file): Python class for handling the SPEAR dataset
│ ├── spear_enhance.py (file): Python script for audio enhancement
│ ├── spear_evaluate.py (file): Python script to compute metrics on the enhanced audio
│ ├── spear_visualise.py (file): Python script to plot and save the computed metrics
│ ├── run_example.sh (file): Bash script run the python scripts
│ └── segments_SET.csv (files): Table of audio chunks of SET, used for metrics computation
│
├── results (directory): Contains computed metrics
│ └── METHOD_SET_D*.csv (files): Table of computed metrics using METHOD for SET in dataset D*
│
├── assets (directory): Contains additional information
│ ├── *SPEAR_logo.png (file): SPEAR logo for _README_
│ ├── **Scripts_blockDiagram.png (file): Diagram for _README_
│ └── **PythonFramework.pptx (file): Presentation for more in depth info on the scripts
│
├── env-spear-metrics.yml (file): Python environment setup file
│
└── README.md (file*): Practical information
Practical Information
The practical information are provided in the README.md file of the git repo.
Analysis Framework Description
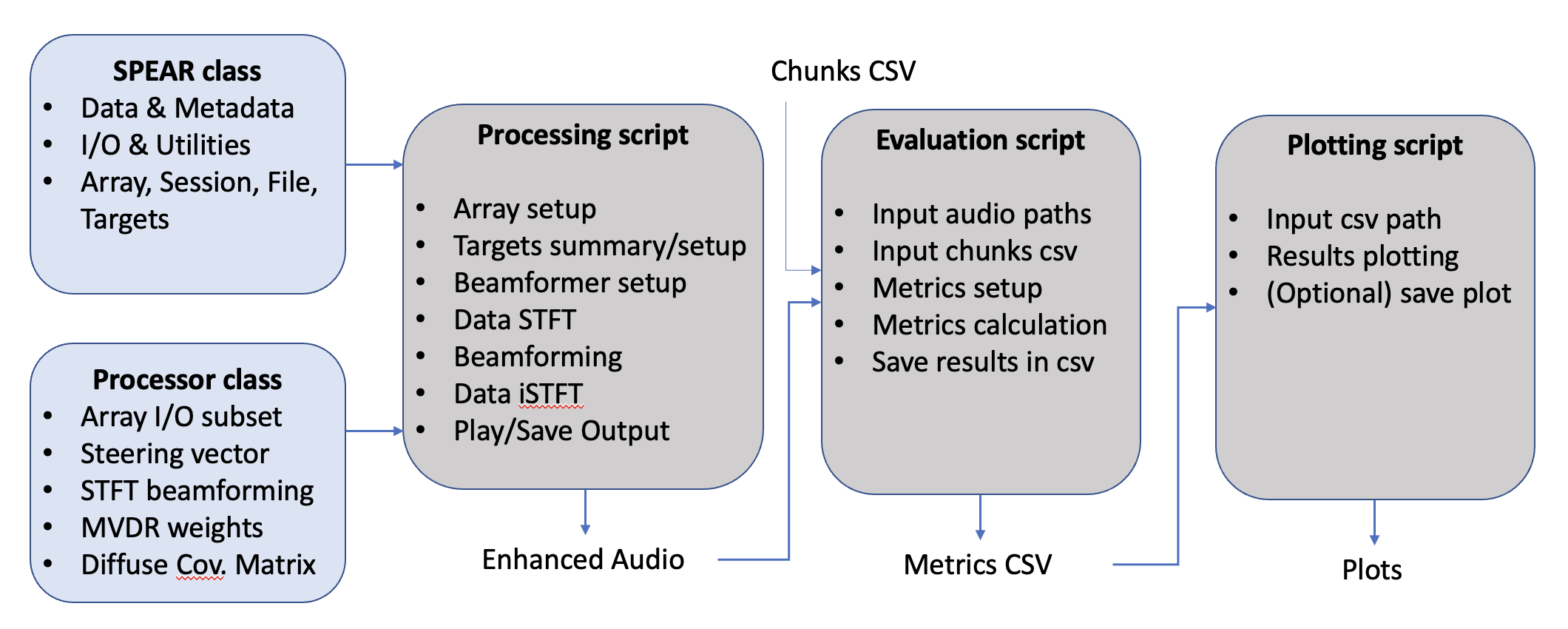 SPEAR Python framework.
SPEAR Python framework.
Scripts
The SPEAR framework consists of two Python classes and three scripts. The SPEAR class is used to handle the datasets and the processor class the enhancement operations. The interested reader is encouraged to investigate the various documented methods. For the sake of brevity, only the main scripts are detailed here.
-
The spear_enhance.py script performs the beamforming on the SPEAR array audio based on the given array orientation and direction of arrival of the current target.
-
The spear_evaluate.py script uses the binaural audio from the processing script and separate it into smaller chunks on which a range of metrics are computed. The chunks selection is made using a pre computed csv file where moments of the dataset are fullfilling a set of pre defined conditions. An example of the output table is seen below.
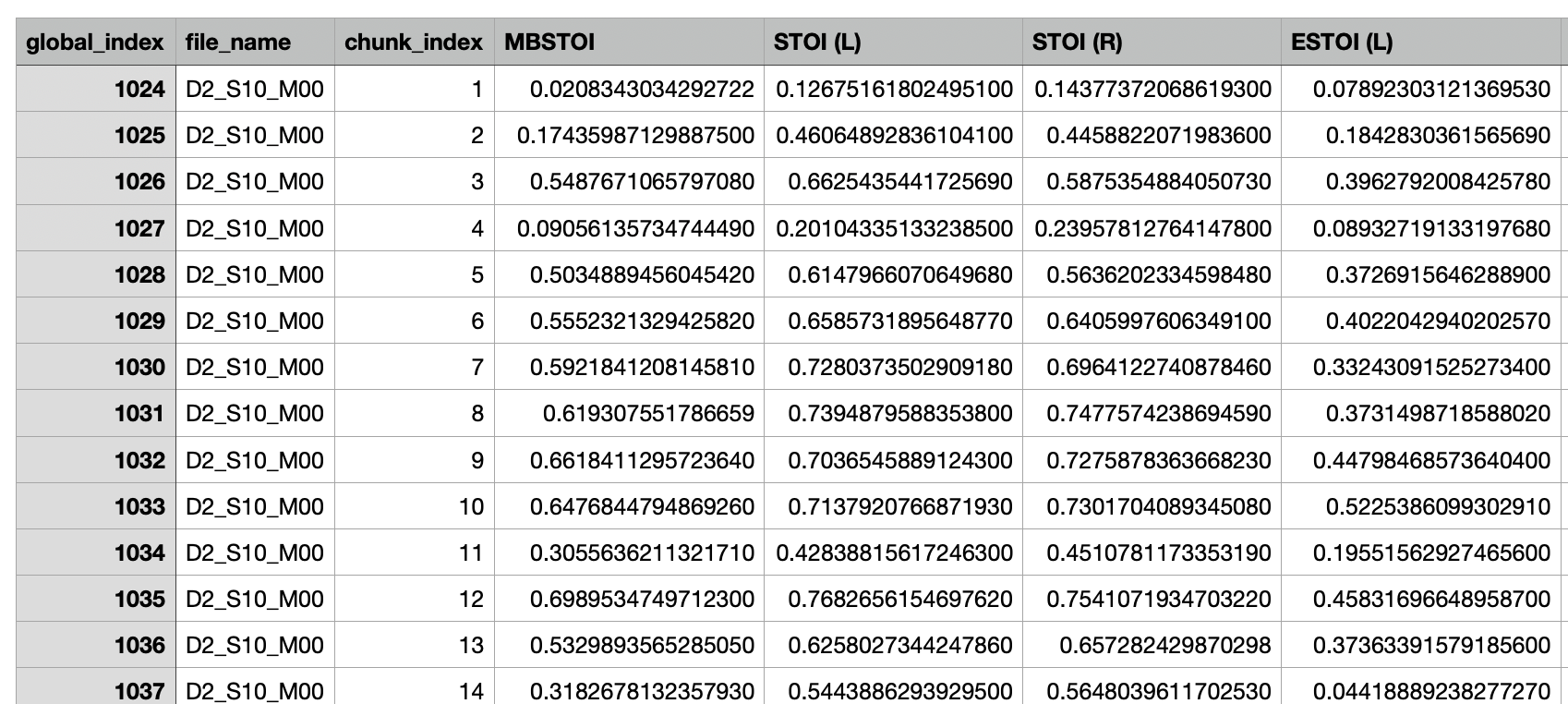 Example output metrics table.
Example output metrics table.
- The spear_visualise.py script uses the output metric table from the batch evaluation to make a box plot distributions of the desired case for all metrics. Absolute metrics values for the passthrough and processed audio are plotted as well as the relative difference between the two. Monaural metrics are computed separately for each ear as observed below.
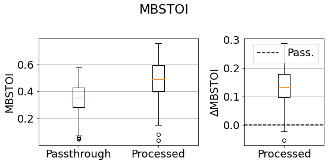 Single box visualisation output for binaural metrics.
Single box visualisation output for binaural metrics.
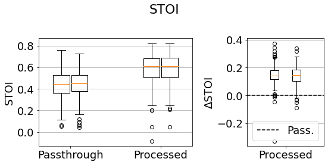 Left/Right ears boxes visualisation output for monaural metrics.
Left/Right ears boxes visualisation output for monaural metrics.
Baseline
The baseline enhancement method used consists of a minimum variance distortionless response (MVDR) beamformer 1 2 assuming isotropic noise. In other words, a stationnary spherically diffuse sound field is assumed. This is equivalent to presuming the presence of interference equally from all directions.
Metrics Calculation
Metrics calculation is done using the following freely available Python packages:
References
-
H. L. van Trees, “Optimum waveform estimation,” Optimum Array Processing, Hoboken, NJ, USA: Wiley, 2002, pp. 428–709. ↩
-
J. Capon, “High-resolution frequency-wavenumber spectrum analysis,” Proc. IEEE, vol. 57, no. 8, pp. 1408–1418, Aug. 1969. ↩
-
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, “An algorithm for intelligibility prediction of time–frequency weighted noisy speech,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2125–2136, 2011. ↩
-
J. Jensen and C. H. Taal, “An algorithm for predicting the intelligibility of speech masked by modulated noise maskers,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 11, pp. 2009–2022, 2016. ↩
-
A. H. Andersen, J. M. de Haan, Z.-H. Tan, and J. Jensen, “Refinement and validation of the binaural short time objective intelligibility measure for spatially diverse conditions,” Speech Communication, vol. 102, pp. 1–13, 2018. ↩
-
J. M. Kates and K. H. Arehart, “The hearing-aid speech perception index (HASPI),” Speech Communication, vol. 65, pp. 75–93, 2014. ↩
-
J. M. Kates and K. H. Arehart, “The hearing-aid speech perception index (HASPI) version 2,” Speech Communication, vol. 131, pp. 35–46, 2021. ↩
-
Y. Hu and P. C. Loizou, “Evaluation of objective quality measures for speech enhancement,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 16, no. 1, pp. 229–238, 2008. ↩ ↩2
-
A. Rix, J. Beerends, M. Hollier, and A. Hekstra, “Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (ICASSP), vol. 2, pp. 749–752 vol.2, 2001. ↩ ↩2
-
E. Vincent, R. Gribonval, and C. F ́evotte, “Performance measurement in blind audio source separation,” IEEE Transactions on Audio, Speech and Language Processing, vol. 14, no. 4, pp. 1462–1469, 2006. ↩ ↩2 ↩3 ↩4
-
J. L. Roux, S. Wisdom, H. Erdogan, J. R. Hershey, “SDR – Half-baked or Well Done?,” IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May 2019. ↩ ↩2 ↩3 ↩4