3 cnn prediction
Predicting Places Categories and correlating with Object Detection Counts¶
In this practical, we will make predictions of place categories using a pre-trained model and will then continue to extract object counts from the images.
Learning Objectives¶
- Use pre-trained model for hold out test-set predictions
- Load model for object detection and run inference on the image dataset
- Examine the counts and correlations with the places scene category
Content¶
- Places Inference
- Tensorflow API
- Object Detection
- Analysis of Results
The Tensorflow API and Object Detection section of this notebook were originally created for the Healthy Data Analytics Course at the School of Public Health, Imperial College London, 2021. The notebook was created by Barbara Metzler, Ricky Nathvani, Esra Suel and Emily Muller.
1. Places Inference¶
In this tutorial we will be using a subset of the Places365 test dataset which we used to train our model. These images should already have been downloaded when running the datadownload.sh script. We will also use our pre-trained model from the previous section 2-cnn-training.md.
# this will allow us to import deep_cnn submodules
import os
import sys
module_path = os.path.abspath(os.path.join('..'))
if module_path not in sys.path:
sys.path.append(module_path)
We are required to initialise the model as per the one which we wish to load. Make sure enter the same model base and number of classes.
from deep_cnn.model_builder import MyCNN
import torch
# enter path to locally saved model
model_path = '../outputs/models/YOUR_PRETRAINED_MODEL_NAME.pt'
# Build model as per pre-trained model
model = MyCNN(model_base='resnet101', n_classes=10)
# load pre-trained model for fine-tuning
checkpoint = torch.load(model_path)
model.load_state_dict(checkpoint['state_dict'])
Next, we will load the data into the dataloader.
from deep_cnn.dataset_generator import dataloader
data_dir='input/places365standard_easyformat/places365_standard/'
root_dir='/home/emily/phd/misc/recode'
# create dataloader
batch_size = 10
params = {
"batch_size": batch_size,
"shuffle": False,
"num_workers": 4,
"pin_memory": False,
"drop_last": False,
}
test_dataloader, _, _ = dataloader(
data_dir, root_dir, "resnet", "val", params
)
print ('There are %s images in the test set' % str(test_dataloader.__len__()*batch_size) )
Run inference on the images
import numpy as np
# INFERENCE
model.train(False)
y = np.zeros((int(len(test_dataloader)), batch_size))
for i, tdata in enumerate(test_dataloader):
test_x = tdata[0]
tlabels = tdata[1].unsqueeze(dim=1)
toutputs = model.forward(test_x)
y[i] = toutputs.cpu().detach().numpy().argmax(axis=1)
predictions = y.flatten()
Now we have the model predictions. Let's convert the numeric output values to category names. We will map them to the folder names:
from pathlib import Path
img_folder='../input/places365standard_easyformat/places365_standard/val/'
folders = Path(img_folder)
dirs = sorted(
os.listdir((folders))
) # read all folder names in alphanumeric order
categories = {}
for i, x in enumerate(dirs):
categories[i] = dirs[i] # map each item in list to name of directory
Putting this altogether, we create a dataframe with image names and predictions. We will merge this with object detections later.
# make dataframe with text based predictions
import pandas as pd
images = Path(img_folder).rglob('*.jpg')
prediction_df = pd.DataFrame([list(sorted(images)), predictions]).T
prediction_df['category'] = prediction_df[1].apply(lambda x: categories[x])
prediction_df['true'] = prediction_df[0].apply(lambda x: str(x).split('/')[-2])
prediction_df['img'] = prediction_df[0].apply(lambda x: str(x).split('/')[-1])
prediction_df['correct'] = prediction_df.apply(lambda x: 1 if x.true == x.category else 0, axis=1)
prediction_df
Let's visualise predictions:
sample = prediction_df.sample(10)
sample
# Visualise predictions
import matplotlib.pyplot as plt
from torchvision.io import read_image
import numpy as np
for i, row in enumerate(sample.iterrows()):
plt.figure(figsize=(8,8))
image = read_image(str(row[1][0])).numpy()
# axs[i].imshow(np.moveaxis(image, 0, -1))
# axs[i].set_title(row[1]['category'])
plt.imshow(np.moveaxis(image, 0, -1))
plt.title(row[1]['category'])
How did the model do? Let's take a look at where it is going wrong specifically:
# visualise bad predictions
sample = prediction_df[prediction_df['correct'] == 0].sample(10)
sample
import matplotlib.pyplot as plt
from torchvision.io import read_image
import numpy as np
for i, row in enumerate(sample.iterrows()):
plt.figure(figsize=(8,8))
image = read_image(str(row[1][0])).numpy()
# axs[i].imshow(np.moveaxis(image, 0, -1))
# axs[i].set_title(row[1]['category'])
plt.imshow(np.moveaxis(image, 0, -1))
plt.title('Pred: ' + row[1]['category'] + 'True: ' + row[1]['true'])
Where does the model go wrong? Does it seem that the model is wrong or the label might be incorrect?
2. Tensorflow API¶
The TensorFlow Object Detection API is an open-source framework built on top of TensorFlow that makes it easy to construct, train and deploy object detection models. There are already pre-trained models in their framework which are referred to as Model Zoo. More info about the Tensorflow API (https://tensorflow-object-detection-api-tutorial.readthedocs.io/en/latest/install.html).
2.1 Installing the TensorFlow API¶
This can be a bit tricky. We will begin by installing packages. Those which are not already present in the Jupyter environment using the !pip command. If you get an error for pip installation. Try adding --user to the end of each line.
!pip install -U --pre tensorflow=="2.*"
!pip install tf_slim
!pip install pycocotools
!pip install seaborn
!pip install geopandas
Get tensorflow/models by cloning the tensorflow/models github repository:
## clone the tensorflow models github repository
import pathlib
import os
if "models" in pathlib.Path.cwd().parts:
while "models" in pathlib.Path.cwd().parts:
os.chdir('..')
elif not pathlib.Path('models').exists():
!git clone --depth 1 https://github.com/tensorflow/models
In order to successfully install the object detection API, you will need to open a bash terminal. Make sure to run the %bash parts of the code in the terminal. Installation will take a few minutes:
%%bash
# cd models/research/
# protoc object_detection/protos/*.proto --python_out=.
# Install TensorFlow Object Detection API.
# cp object_detection/packages/tf2/setup.py .
# python -m pip install .
To load the object detection utils, change into the models/research directory which we cloned from github above (your path might be different to adjust as necessary):
print (os.getcwd())
os.chdir('models/research')
print (os.getcwd())
# change back to the root directory afterwards
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as viz_utils
os.chdir('../..')
print (os.getcwd())
Great we now have access to TensorFlow Object Detection API where we will load the Object Detection model from.
3. Object detection¶
In this section, we will introduce the object detection architecture, install the Tensorflow Object Detection API, load the model and run inference on the dataset.
3.1 Choosing a model architecture: MobileNet-SSD¶
The two stage Object Detection algorithm named Faster R-CNN is made up of the region proposal network (RPN) and the detection network. This architecture continues to feature in some of the top performing networks (see https://paperswithcode.com/sota/object-detection-on-coco).
However, in the interest of processing time and memory, we chose the MobileNet-SSD for the tutorial.
Depending on your time/accuracy trade-off, you can choose the appropriate model from the TensorFlow API. If we want a high-speed model the single-shot detection (SSD) network works best. As its name suggests, the SSD network determines all bounding box probabilities in one go; hence, it is much faster than the two stage R-CNN. The SSD architecture is a single convolution network that learns to predict bounding box locations and classify these locations in one pass. Hence, SSD can be trained end-to-end. The SSD network consists of a base architecture (MobileNet in this case) followed by several convolution layers:
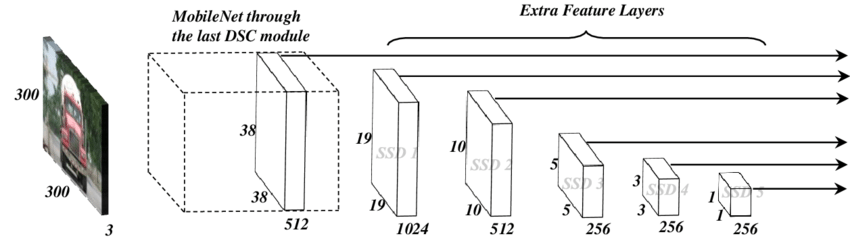
The SSD's operates on feature maps to detect the location of bounding boxes. Recall – a feature map is of the size Df Df M. For each feature map location, k bounding boxes are predicted. Each bounding box carries with it the following information:
- 4 corner bounding box offset locations (cx, cy, w, h)
- C class probabilities (c1, c2, …cp)
SSD does not predict the shape of the box, rather just where the box is. The k bounding boxes each have a predetermined shape. The shapes are set prior to actual training. For example, in the figure above, there are 5 boxes, meaning k=5.
import numpy as np
import pandas as pd
import tensorflow as tf
import time
from matplotlib import pyplot as plt
from PIL import Image
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
import warnings
warnings.filterwarnings('ignore') # Suppress Matplotlib warning
%matplotlib inline
3.2 Load Model¶
Since we have successfully downloaded the Object Detection API, we will load the SSD MobileNet model.
The code snippet shown below is used to download the pre-trained object detection model we shall use to perform inference. The particular detection algorithm we will use is the SSD mobilenet 640x640. More models can be found in the TensorFlow Object Detection Model Zoo (https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/tf2_detection_zoo.md):
# Download and extract model
def download_model(model_name, model_date):
base_url = 'http://download.tensorflow.org/models/object_detection/tf2/'
model_file = model_name + '.tar.gz'
model_dir = tf.keras.utils.get_file(fname=model_name,
origin=base_url + model_date + '/' + model_file,
untar=True)
return str(model_dir)
MODEL_DATE = '20200711'
MODEL_NAME = 'ssd_mobilenet_v2_fpnlite_640x640_coco17_tpu-8'
PATH_TO_MODEL_DIR = download_model(MODEL_NAME, MODEL_DATE)
Next, we download the labels file (.pbtxt). This contains a list of strings used to add the correct label to each detection (e.g. person). Since the pre-trained model we will use has been trained on the COCO dataset, we will need to download the labels file corresponding to this dataset, named mscoco_label_map.pbtxt:
# Download labels file
def download_labels(filename):
base_url = 'https://raw.githubusercontent.com/tensorflow/models/master/research/object_detection/data/'
label_dir = tf.keras.utils.get_file(fname=filename,
origin=base_url + filename,
untar=False)
label_dir = pathlib.Path(label_dir)
return str(label_dir)
LABEL_FILENAME = 'mscoco_label_map.pbtxt'
PATH_TO_LABELS = download_labels(LABEL_FILENAME)
Next we load the model:
PATH_TO_SAVED_MODEL = PATH_TO_MODEL_DIR + "/saved_model"
print('Loading model...', end='')
start_time = time.time()
# Load saved model and build the detection function
detect_fn = tf.saved_model.load(PATH_TO_SAVED_MODEL)
end_time = time.time()
elapsed_time = end_time - start_time
print('Done! Took {} seconds'.format(elapsed_time))
3.3 Load label map data (for plotting)¶
Label maps join numerical indices to category names, so that when the CNN predicts 5, we know that this corresponds to the object: airplane. Here we use internal utility functions, but anything that returns a dictionary mapping integers to appropriate string labels would be fine.
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS,
use_display_name=True)
3.4 Running Inference on the Image Dataset¶
The code shown below loads an image, runs it through the detection model and visualizes the detection results, including the keypoints.
Note that this will take a long time (several minutes) the first time you run this code due to tf.function’s trace-compilation — on subsequent runs (e.g. on new images), things will be faster.
Print out detections[‘detection_boxes’] and try to match the box locations to the boxes in the image. Notice that coordinates are given in normalized form (i.e., in the interval [0, 1]).
Set min_score_thresh to other values (between 0 and 1) to allow more detections in or to filter out more detections.
img_folder = '../input/places365standard_easyformat/places365_standard/val/'
def load_image_into_numpy_array(path):
"""Load an image from file into a numpy array.
Puts image into numpy array to feed into tensorflow graph.
Note that by convention we put it into a numpy array with shape
(height, width, channels), where channels=3 for RGB.
Args:
path: the file path to the image
Returns:
uint8 numpy array with shape (img_height, img_width, 3)
"""
return np.array(Image.open(path))
def run_inference_for_single_image(model, image):
image = load_image_into_numpy_array(image)
# The input needs to be a tensor, convert it using `tf.convert_to_tensor`.
input_tensor = tf.convert_to_tensor(image)
# The model expects a batch of images, so add an axis with `tf.newaxis`.
input_tensor = input_tensor[tf.newaxis,...]
# Run inference
#model_fn = model.signatures['serving_default']
output_dict = model(input_tensor)
# All outputs are batches tensors.
# Convert to numpy arrays, and take index [0] to remove the batch dimension.
# We're only interested in the first num_detections.
num_detections = int(output_dict.pop('num_detections'))
output_dict = {key:value[0, :num_detections].numpy()
for key,value in output_dict.items()}
output_dict['num_detections'] = num_detections
# detection_classes should be ints.
output_dict['detection_classes'] = output_dict['detection_classes'].astype(np.int64)
# Handle models with masks:
if 'detection_masks' in output_dict:
# Reframe the the bbox mask to the image size.
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
output_dict['detection_masks'], output_dict['detection_boxes'],
image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(detection_masks_reframed > 0.5,
tf.uint8)
output_dict['detection_masks_reframed'] = detection_masks_reframed.numpy()
return image, output_dict
Let's visualise inference on just 5 of the images:
i = 0
for image_path in Path(img_folder).rglob('*.jpg'):
print('Running inference for {}... '.format(image_path), end='')
# RUN INFERENCE
image_np, detections = run_inference_for_single_image(detect_fn, image_path)
# Visualise Detection
image_np_with_detections = image_np.copy()
viz_utils.visualize_boxes_and_labels_on_image_array(
image_np_with_detections,
detections['detection_boxes'],
detections['detection_classes'],
detections['detection_scores'],
category_index,
use_normalized_coordinates=True,
max_boxes_to_draw=200,
min_score_thresh=.50,
agnostic_mode=False)
plt.figure()
plt.imshow(image_np_with_detections)
print('Done')
i += 1
if i == 5:
break
plt.show()
#sphinx_gallery_thumbnail_number = 2
The Tensorflow API saves the results the in the detection object that contains multiple dictionaries:
for i in detections:
print (i)
Now we will run inference on the entire dataset, storing the detection results in a dictionary:
def run_on_all_images(img_folder='../input/places365standard_easyformat/places365_standard/val/'):
output_dicts = []
images = Path(img_folder).rglob('*.jpg')
corrupts = []
for ix, image in enumerate(images):
try:
im, output_dict = run_inference_for_single_image(detect_fn, image)
#print (images[ix])
output_dicts.append(output_dict)
except:
corrupts.append(image)
print ('Run inference on image %s' % ix)
return output_dicts, corrupts
%%capture
import time
start_time = time.time()
det, corrupts = run_on_all_images(img_folder)
end_time = time.time()
print ('Takes %s seconds to run' % str(end_time - start_time))
3.5 Converting detected objects into DataFrame¶
We will make the data more manageable for subsequent analysis
detect_scores = []
detect_classes = []
detect_ymin = []
detect_xmin = []
detect_ymax = []
detect_xmax = []
Id_list = []
images = Path(img_folder).rglob('*.jpg')
for img, output_dict in zip(images, det):
cut_off_scores = len(list(filter(lambda x: x >= 0.5, output_dict['detection_scores'])))
detect_score = []
detect_class = []
for j in range(cut_off_scores):
detect_score.append(output_dict['detection_scores'][j])
detect_class.append(output_dict['detection_classes'][j])
detect_scores.append(detect_score)
detect_classes.append(detect_class)
fname = os.path.basename(img)
Id_list.append(fname)
#Id_list.append()
Detected_objects = pd.DataFrame(
{'Image': Id_list,
'Score': detect_scores,
'Class': detect_classes})
Detected_objects.head()
Detected_objects.shape
## Create a dictionary with the labels from the COCO dataset
coco_dict = category_index.values()
coco = pd.DataFrame(coco_dict)
coco = pd.Series(coco.name.values,index=coco.id).to_dict()
4 Analysis of Results¶
Let's perform some analysis to find out more about the features extracted from the model.
We will first create a function to plot total object counts:
# Create a row for each Class element
lst_col = 'Class'
df = pd.DataFrame({
col:np.repeat(Detected_objects[col].values, Detected_objects[lst_col].str.len())
for col in Detected_objects.columns.drop(lst_col)}
).assign(**{lst_col:np.concatenate(Detected_objects[lst_col].values)})[Detected_objects.columns]
df = df.drop('Score', axis = 1)
# Maps class integer to object name
df['Name'] = df['Class'].astype(int)
df['Name'] = df['Name'].map(coco)
# plot total counts across all images
df['Name'].value_counts().plot.bar(figsize=(20,20))
plt.title('Object counts across all images')
plt.show()
Let's take a look at the correlations between objects counts in a single image, across all images. What objects tend to appear together in the imagery?
# plot correlations between counts in a single image, across all images
### POINT BASED ANALYSIS
obj_df_img = pd.crosstab(df.Image, df.Name)
obj_df_img = obj_df_img.groupby(['Image']).sum()
obj_df_img.head()
obj_df_img.columns
plt.figure(figsize=(20,20))
corr = obj_df_img.corr()
ax = sns.heatmap(corr, cmap="YlGnBu").set_title("Correlation matrix: pairwise correlation of the dected object classes")
The correlations are not weighted by the number of occurences. Consider plotting the heatmap normalised by object counts across all images.
4.1 Correlation between scene category predictions and object detections¶
# merge predictions to object detections
obj_df_img['img'] = obj_df_img.index
merged = prediction_df.merge(obj_df_img)
merged.head()
merged.groupby('category').sum()
totals = merged.groupby('category').sum()
totals = totals[totals.columns[totals.sum()>5]] # only consider objects which are counted more than 5 times across all images. Easier to visualise
totals.plot.bar(figsize=(20,20))
plt.show()
What patterns do you notice with each of the categories and object counts? Does anything strike you as unexpected? Or do these predictions fit with your own reasoning?
5 Further Analysis¶
Object Detections add a layer of interpretability to our analysis because they are localized labelled objects which tell us what make up the image. The CNN is opaque, unless we explore model-based methods of interpretability, typically called pixel-attribution methods.
Try using pythons scikitlearn library to build a classifier to predict class outcome using the object detection counts.
Do you think it would perform better than the CNN or worse? If there are 10 classes, then an accuracy of more than 0.1 is better than random. Consider what else the CNN might be able to detect beyond the object detections made by the object detection network.